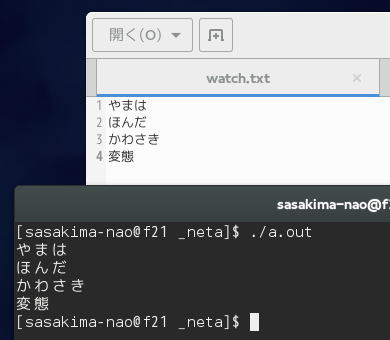
ファイル名の数値優先ソート C 言語版を書いてみた。
というより、手元に溜まっている古い覚書ファイルを整理している。
昔書いたのって posix と glib が混在で自分がゲンナリするもので。
とにかく今の知識で限界まで整理して Web に書き出す。
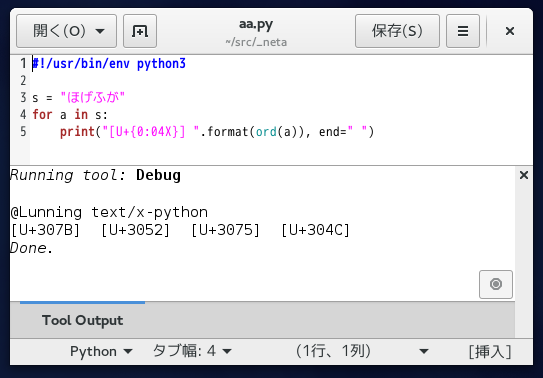
Python の覚書でディレクトリ内容列挙とソートを別々に書いているけど
どうせ同時に使うのだからまとめたほうがよさそう。
ということでこんなコードになった。
#include <glib.h>
#include <gio/gio.h>
/*
* Numeric sort in GLib (like a Nautilus)
* gcc nautilus_sort.c `pkg-config --cflags --libs gio-2.0`
**/
gint
compare_main_func(gchar** a, gchar** b) {
gint n;
gchar* aaa = g_utf8_collate_key_for_filename (*a, -1);
gchar* bbb = g_utf8_collate_key_for_filename (*b, -1);
n = g_strcmp0(aaa, bbb);
g_free(aaa);
g_free(bbb);
return n;
}
gint
compare_data_func(gconstpointer a, gconstpointer b) {
return compare_main_func((gchar**)a, (gchar**)b);
}
void
print_data(gpointer data, gpointer user_data) {
g_printf("%s\n", data);
}
int
main (int argc, char *argv[]) {
gchar* dir;
GFile* file;
GFileEnumerator* file_enum;
GFileInfo* info;
GPtrArray* array;
dir = g_get_current_dir();
file = g_file_new_for_path(dir);
g_free(dir);
/* Get the directory contents */
array = g_ptr_array_new();
file_enum = g_file_enumerate_children(file,
G_FILE_ATTRIBUTE_STANDARD_DISPLAY_NAME,
G_FILE_QUERY_INFO_NONE,
NULL,
NULL);
for (;;) {
info = g_file_enumerator_next_file(file_enum, NULL, NULL);
if (info == NULL) break;
g_ptr_array_add(array, g_strdup(g_file_info_get_display_name(info)));
g_object_unref(info);
}
g_object_unref(file_enum);
/* Sort */
g_ptr_array_sort(array, compare_data_func);
/* print */
g_ptr_array_foreach(array, print_data, NULL);
/* free */
g_ptr_array_free(array, TRUE);
return 0;
}
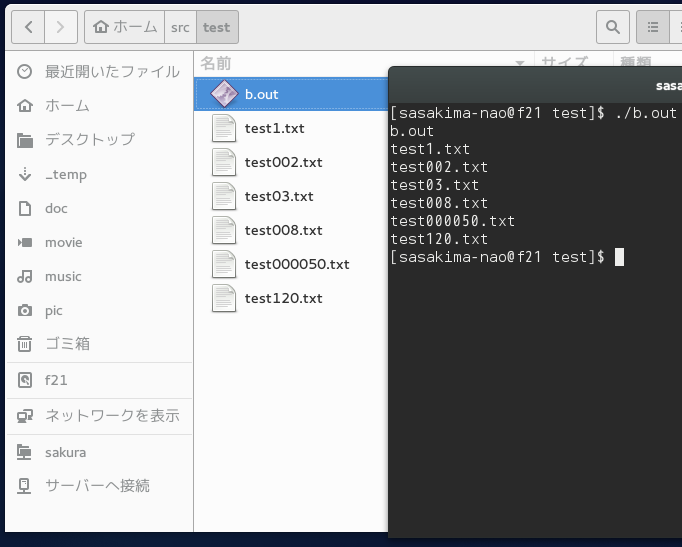
pkg-config は gio ですのでお間違いなく。
Python では使わないので気が付かなかったけど
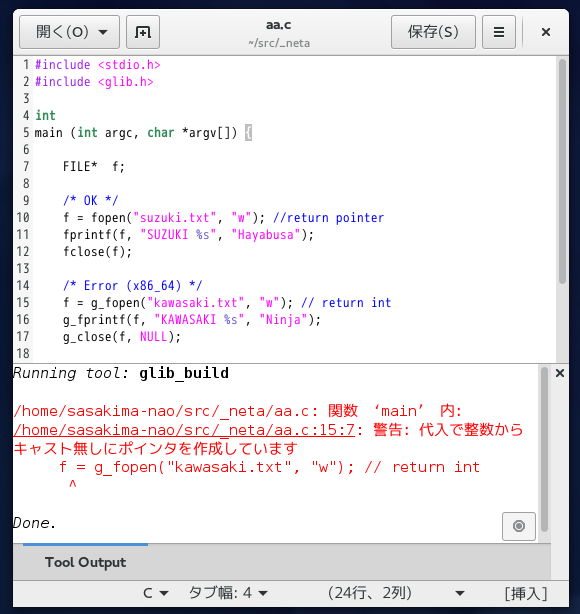
GCompareFunc の引数が gconstpointer になっている。
実際には const gchar** だ、コレにはまいった。
gchar* aaa = g_utf8_collate_key_for_filename (*((gchar**)a), -1);
とやれば一応関数に分離せずにビルドできる。
けど見た目が酷過ぎるので分離した、ドンだけキャストすればいいのよ。
ポインタが今一。。。な初心者がこんなの見たらブン投げるわ。
しかし GLib はループ用の int をまったく使わないで書けるんだな。
筆者はもう慣れたけどローカル変数も malloc も使わないって違和感スゲェ。
C より Python の経験があるほうが覚えるの早そう、破棄が必要なだけだし。
ついでに、今日電源を入れたら。

GNOME はこんなに親切だったのか、初めて見た。
いやマウスの LED がチカチカするから解るんですけど。