#include <stdio.h>
#include <glib.h>
int
main (int argc, char *argv[]) {
FILE* f;
/* OK */
f = fopen("suzuki.txt", "w"); //return pointer
fprintf(f, "SUZUKI %s", "Hayabusa");
fclose(f);
/* Error (x86_64) */
f = g_fopen("kawasaki.txt", "w"); // return int
g_fprintf(f, "KAWASAKI %s", "Ninja");
g_close(f, NULL);
/* No Error (x86_64)
gint n = g_fopen("kawasaki.txt", "w"); // return int
g_close(n, NULL); */
return 0;
}
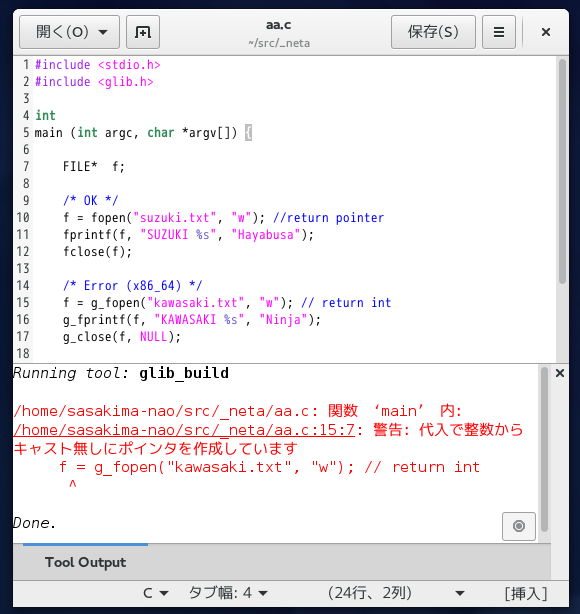
おいおい、どういうことだよ。
devhelp をよく見ると「コレは Windows の表記だ」とあるが。
fopen にマッピングではなく stat に合わせているのか?
glibc は glib のサブセットだと思いこんでいたけど違うんだな。
つまり Linux では FILE* は使わないほうがいいということみたい。
x86(32bit) だと気が付かないで混乱するかも。
glib – C言語で、UTF-8 の文字列から Unicode のコードポイントを取得するやりかた – Qiita
g_utf8_to_ucs4_fast って fast だから速いのかな?
GLib ってまだまだ知らないことが沢山あるな。
ただコードポイントを取得なら Python3 のほうが簡単そう。
単文字を ord() すれば UCS-4 のまま値が取れそうだけど、試すか。
文字コード考え方から理解するUnicodeとUTF-8の違い | ギークを目指して
「ほげふが」が [U+307B] [U+3052] [U+3075] [U+304C]
になれば OK ということね。
#!/usr/bin/env python3
s = "ほげふが"
for a in s:
print("[U+{0:04X}] ".format(ord(a)), end=" ")
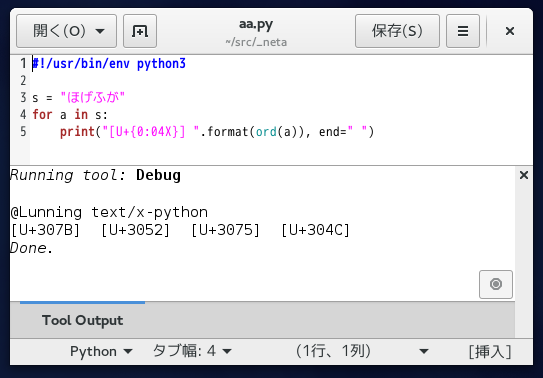
思ったとおり。
ワイド文字が UTF-16 になる Windows 版じゃ変換が必要だけど。
ごめん Windows Python3 でも IronPython でもできるわ
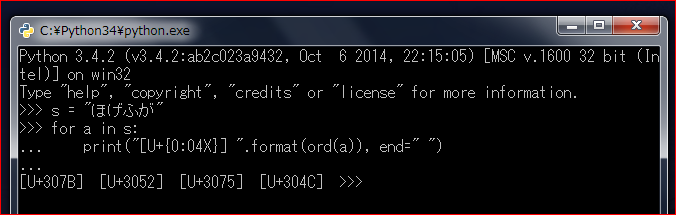

Linux は GLib が簡単に使えて Python も実用的。
やはりプログラミングするなら Linux ですよ。