glib での読み書きは g_open ではなく GIOChannel で行うらしい。
もう情報が山ほどありすぎてワケワカだよ、独学の限界を感じる。
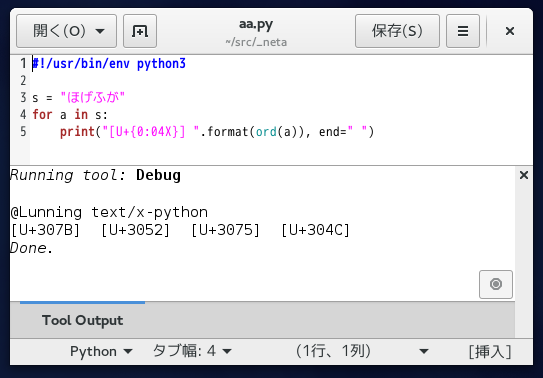
まだよく解っていないけどとりあえずテキストで試してみた。
#include <glib.h>
int
main(int argc, char* argv[]) {
GIOChannel* channel;
GError* error = NULL;
gchar* str;
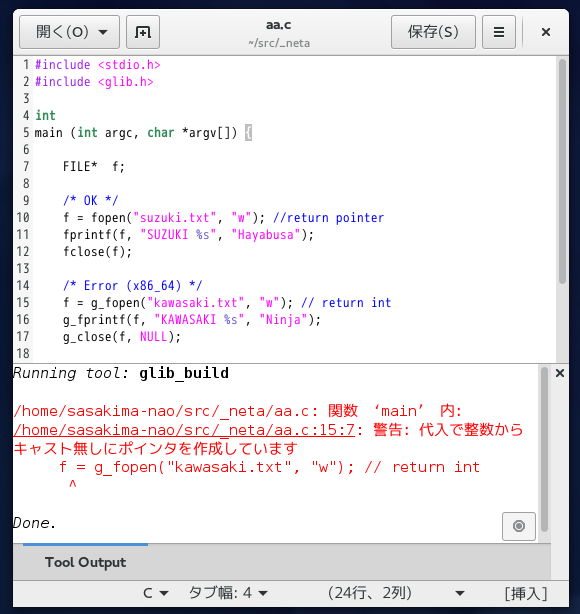
gsize length;
#if !GLIB_CHECK_VERSION (2,35,0)
g_type_init ();
#endif
channel = g_io_channel_new_file("watch.txt", "r", &error);
if (error)
{
g_warning (error->message);
g_error_free (error);
return 1;
}
g_io_channel_read_to_end(channel, &str, &length, &error);
if (error)
{
g_warning (error->message);
g_error_free (error);
g_io_channel_unref(channel);
return 1;
}
g_printf(str);
g_free(str);
g_io_channel_unref(channel);
return 0;
}
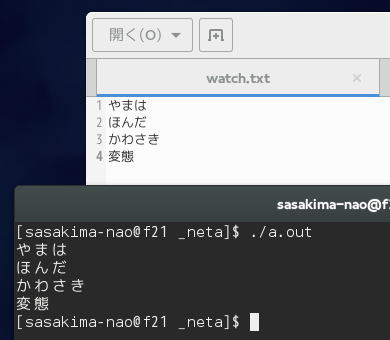
こういうことでいいのかな?
char 配列ならバイト単位だからバイナリにも応用できるな。
んで、いつものように vala のサンプルコードを見てみる。
GLib.IOChannel ? glib-2.0
g_io_add_watch でハンドラを用意してメインループを回している。
このコードだとこうするメリットが特に見当たらないんですけど。
GMainLoop, GMainContext和GSource学?笔? – ?匠Smith先生的?? – 博客?道 – CSDN.NET
こんなこともできるのか、端末からの読み書きに GMainLoop とは。
つまりメインループを回すことに意義があるってことかな。
ただバックスラッシュ(\)がスラッシュ{/}になっているのは何故?
そこを書き換えて g_type_init を消せば普通にビルドできます。
このコードを参考に色々弄ってみると面白いかも。
中国にも glib を使っている人がいるんだな、つか日本人は…