Comipoli beta2 のメモリ展開に凄い問題が見つかった。
3000x4000px over の画像を役二百枚まとめた CBZ を試しに作ってみた。
ソレを読み込むと…
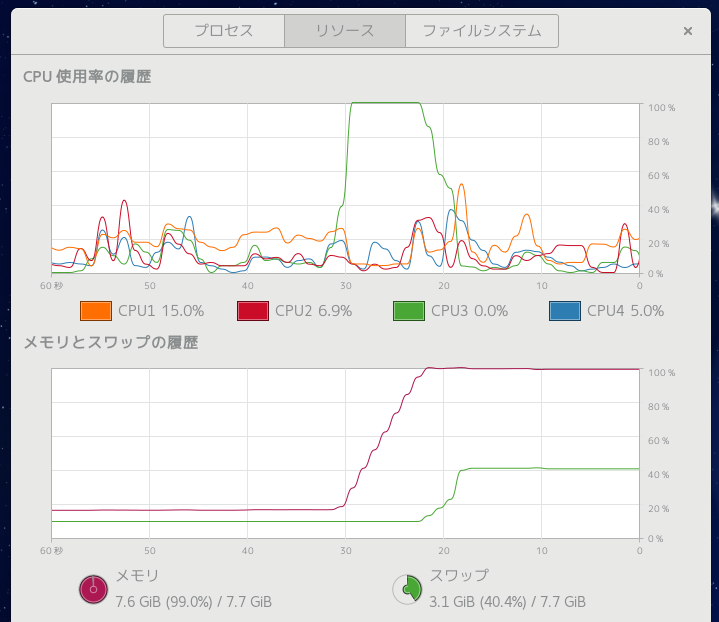
8GB もあるメモリがアッサリ埋まって swap 領域に突入。
SSD だから我慢できる程度の遅さだけど HDD だと死ねるレベル。
JPEG 圧縮を zip 圧縮しているからファイルサイズは 150MB 程度なのに。
GdkPixbuf に展開するとこんなサイズになってしまうのか。
16GB あれば、、、、、いやそうじゃない。
とにかくメモリ使用量をなんとかしなきゃ。
都度読み込みならたとえ 100000x100000px でも問題無い…
そこまでいくと展開が超遅くなるから誰もやらないってばさ。
JPEG を GdkPixbuf に変換せずにバイナリのまま配列なら…
前後処理丸ごと作り替えになるし表示効率も悪くなるな。
そもそも Python でバイナリの配列も実体はポインタなのかな?
ここらは C でやったほうがモヤモヤしなくて済むのだが。
単純に一定の大きさ以上は縮小が一番効率良さげ。
現在のディスプレイ市場は 1080p が主流。
ならば 1080p よりデカいなら縮小という手段が多分最高効率だと思う。
def iter_zip(self):
# unzip
with zipfile.ZipFile(self.zip.get_path()) as o:
l = o.namelist()
l.sort()
self.datas.clear()
for name in l:
ext = os.path.splitext(name)[1].lower()
if ext == ".jpg" or ext == ".jpeg" or ext == ".png":
data = o.read(name)
stream = Gio.MemoryInputStream.new_from_data(data)
p = GdkPixbuf.Pixbuf.new_from_stream(stream)
# Escape Swap
if p.get_height() > 1080:
rate = p.get_width() / p.get_height()
p = GdkPixbuf.Pixbuf.scale_simple(p, 1080 * rate, 1080, GdkPixbuf.InterpType.BILINEAR)
stream.close()
yield p
手抜きに見えるけどフルスクリーン時の描写処理が速くなるメリットがある。
と思えるけど Comipoli ではソコは OpenGL がやるので無意味なことは秘密だよ。
いや問題はメモリ使用量だってば!
再起動して同じファイルを読み込んでみる
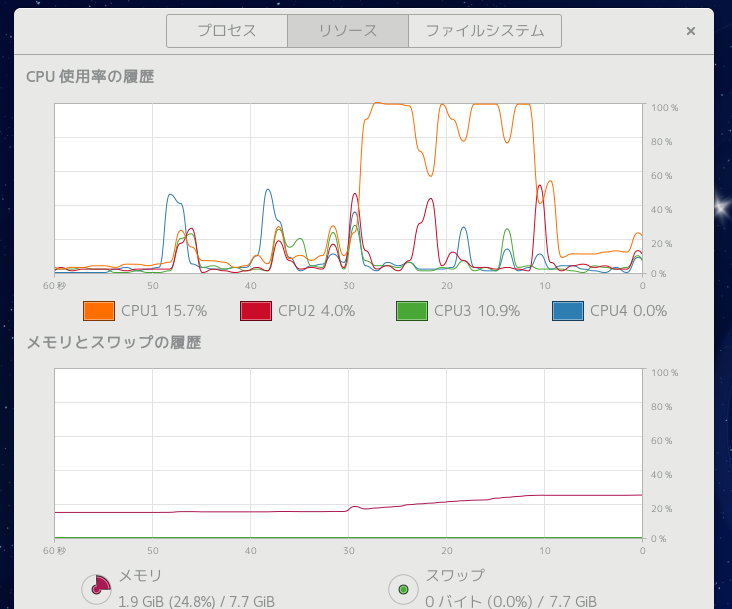
1/10 以下に、まさかこんなに違うとは。
これだったらメモリは 4GB あれば問題無さそう、今時なら普通だよね。
でもやはり展開時間は倍近くになる。
バックグラウンド展開だから気にならないとはいえ、やはり遅い。
czipfile なんて早いらしいモジュールは Python2 用しか見当たらない。
ただデータの転送量が減るおかげか動作が少し速くなるメリットも。
とりあえず又問題が出るまでコレでいこう、まだベータだし。